背景
通常用Cloudflare Workers来实现一个Function或者定时任务或者使用“Edge”模式运行Nextjs,但是如果直接想用Workers来部署“runtime”模式的Nextjs则需要进行一些调整。使用Nextjs的AppRoute来调用Huggingface的AI推理api。 并不是所有模型都可以通过推理sdk来调用的,我在后面会写如何找到支持的模型
OpenNext
OpenNext是一个开源项目,主要是把AWS Lambda,Cloudflare Workers,Netlify sites转换为“runtime”模式的nextjs项目
初始化
为了方便引用,我把两个页面都放一下:
| 网站 | 链接 |
|---|---|
| Cloudflare | https://developers.cloudflare.com/workers/framework-guides/web-apps/nextjs/ |
| OpenNext | https://opennext.js.org/cloudflare |
| HuggingFace | https://huggingface.co/docs/huggingface.js/en/inference/README |
初始化项目,并安装
npm create cloudflare@latest -- <project-name> --framework=next --platform=workers
过程中直接按Enter接受默认值即可,最后进入项目目录,并安装packages
cd <project-name>
npm i
安装huggingface
npm install @huggingface/inference
创建HF的Access token
注册并登陆Huggingface,进入右上角的用户菜单,选“Settings”,打开后,进入“Access Tokens”
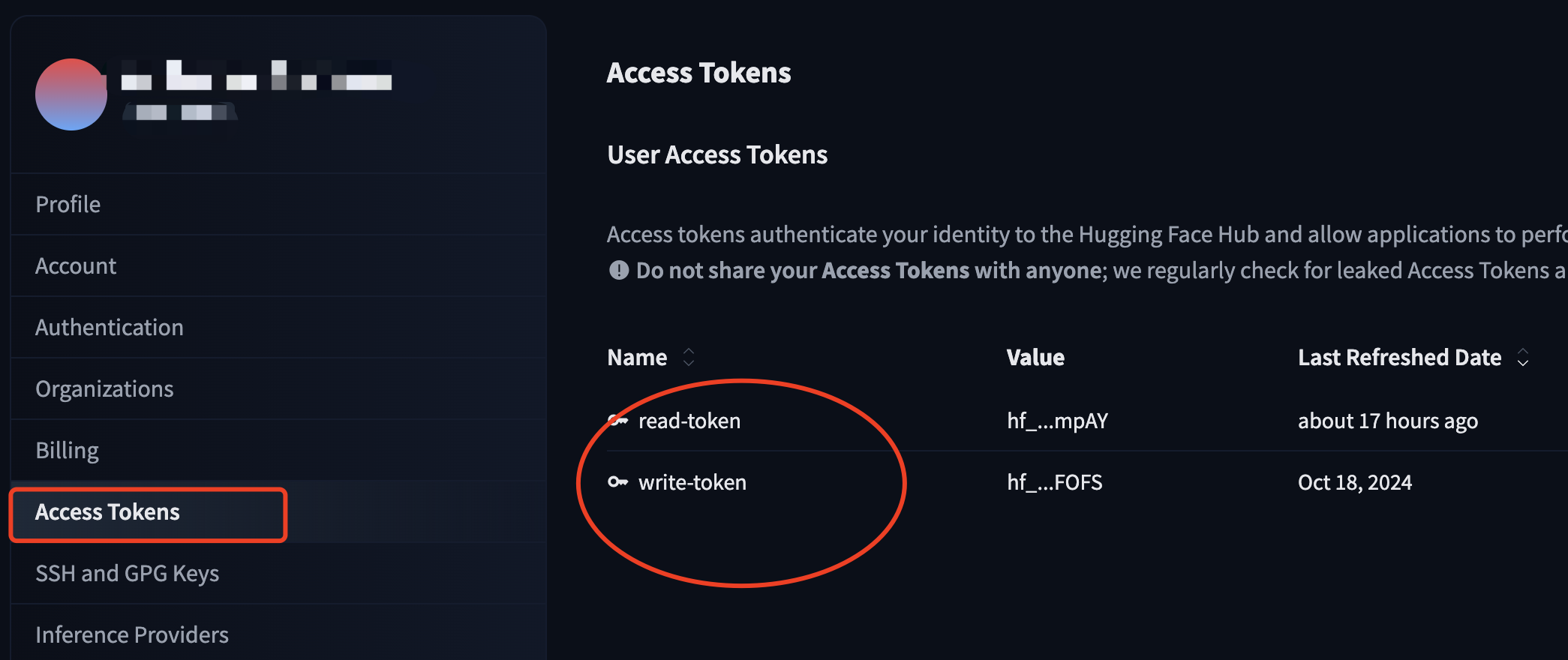
这里可以新建一个只读token
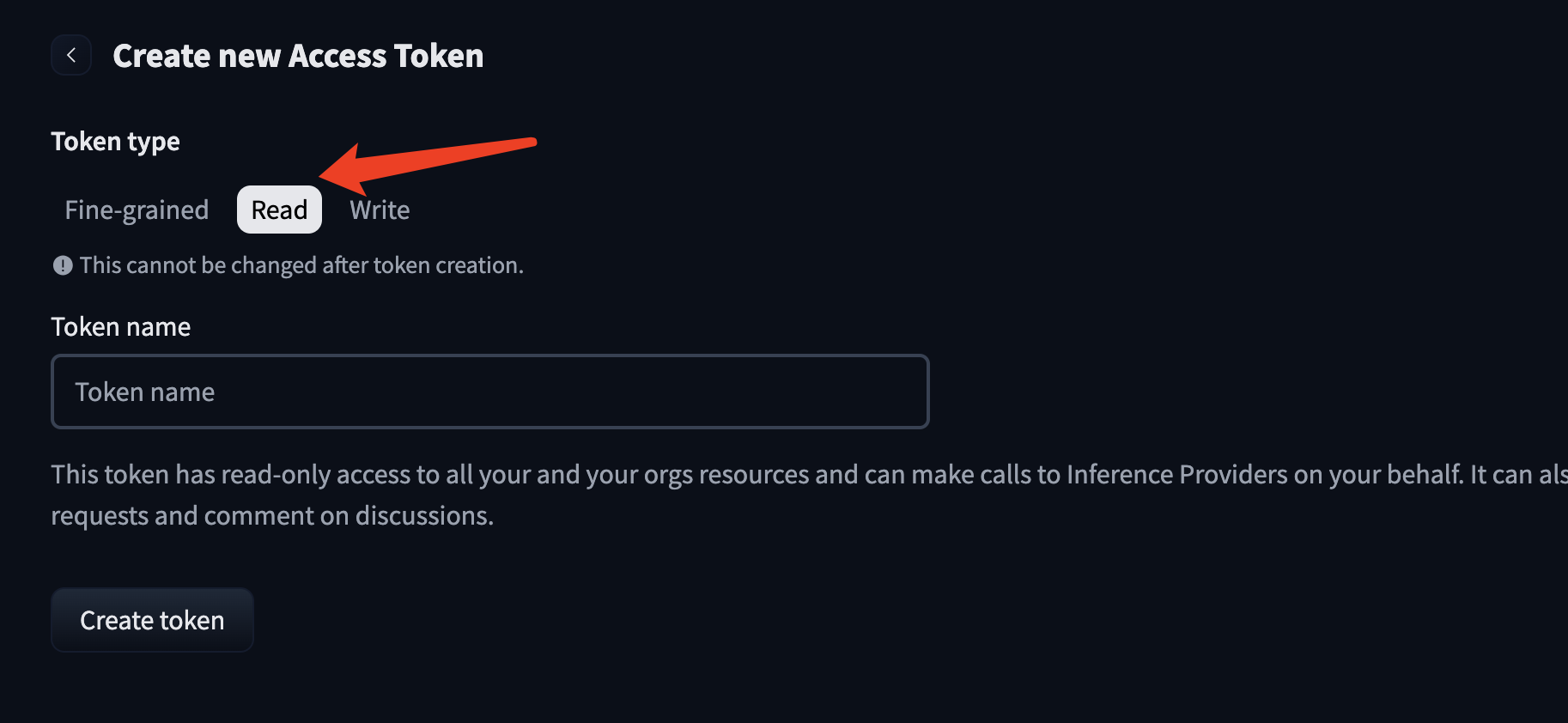
注意妥善保管token,只有一次机会拷贝,最好用密码管理工具保存起来,这样就不会找不到。完全自托管的bitwarden教程在这里
添加一个api endpoint
现在可以为nextjs添加一个api endpoint了,因为我们创建App route模式,添加api端点非常容易,创建src/app/app/hfai/route.js即可
该文件的实现为:
import { InferenceClient } from '@huggingface/inference';
import { NextResponse } from 'next/server';
import { getCloudflareContext } from "@opennextjs/cloudflare";
export async function POST(req) {
const ctx = await getCloudflareContext();
try {
let hf = new InferenceClient(ctx.env.HF_API_TOKEN || process.env.HF_API_TOKEN);
const response = await hf.chatCompletion({
// model: "Qwen/Qwen3-32B",
// provider: "cerebras",
// model: "deepseek-ai/DeepSeek-R1-0528",
// provider: "fireworks-ai",
model: "HuggingFaceTB/SmolLM3-3B",
provider: "hf-inference",
messages: [{ role: "user", content: "Hello, nice to meet you!" }],
max_tokens: 512,
temperature: 0.1,
});
return NextResponse.json(response);
} catch (error) {
console.error(error);
return NextResponse.json({ error: error.message }, { status: 500 });
}
}
这样通过Postman或者Bruno或者curl访问对应的api就可以得到模型的响应。
npm run dev
curl -X POST http://localhost:3000/api/hfai
注意点
找到对应的模型名称和provider
并不是所有HF上的模型都可以直接使用HF推理sdk,我们需要找出哪些模型支持。 首先进入HF首页找到最上面的Models,从左侧的面板找到Others,在下面会显示推理模型提供商Inference Providers,这里会列出所有支持推理sdk的模型,再通过其他的过滤器如task我们可以找到某个一个provider提供的某一类推理模型,比如图中为huggingface的一个文本生成模型
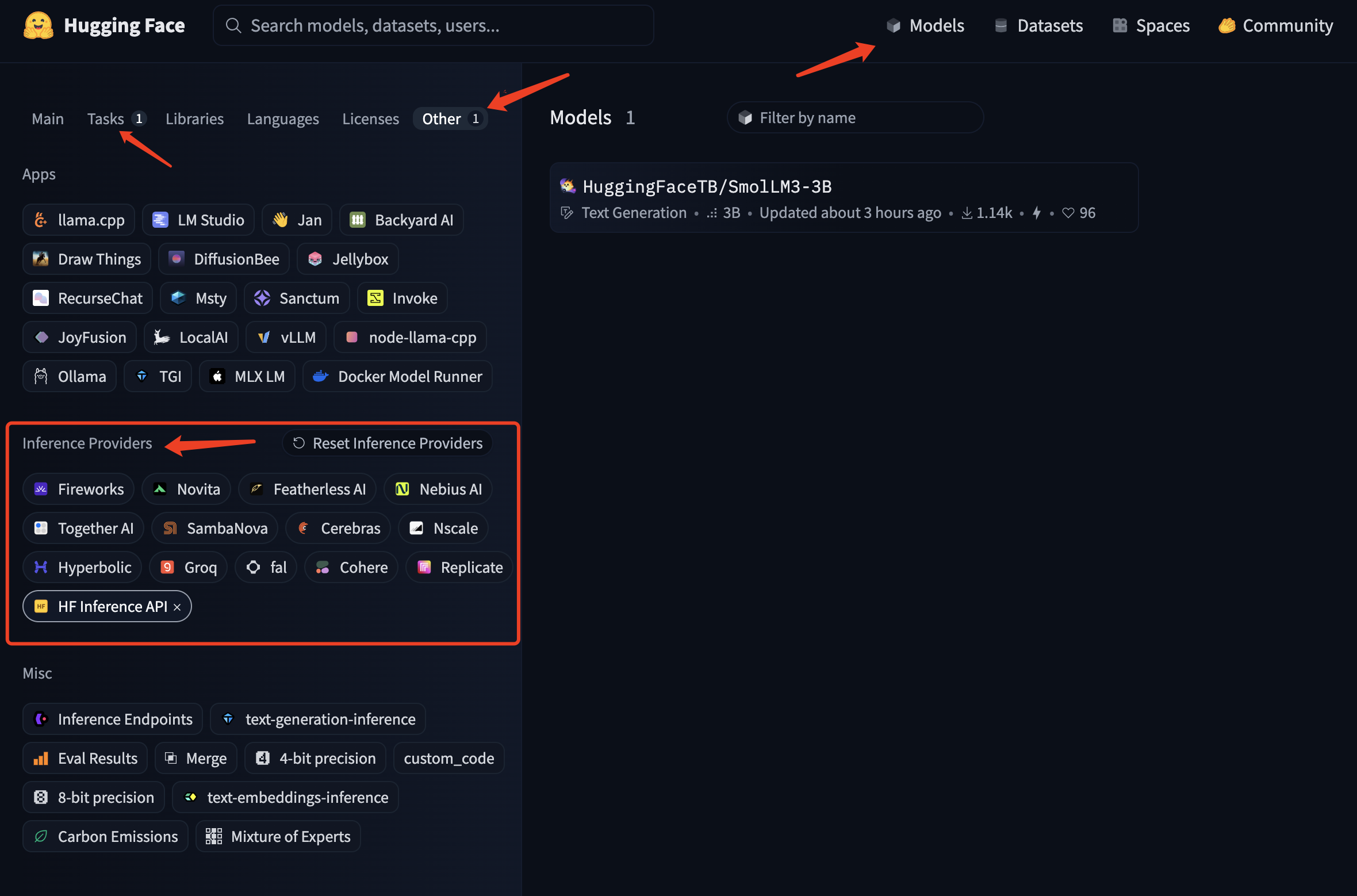 目前所有provider的名称:
目前所有provider的名称:
Available providers: black-forest-labs,cerebras,cohere,fal-ai,featherless-ai,hf-inference,fireworks-ai,groq,hyperbolic,nebius,novita,nscale,openai,ovhcloud,replicate,sambanova,together
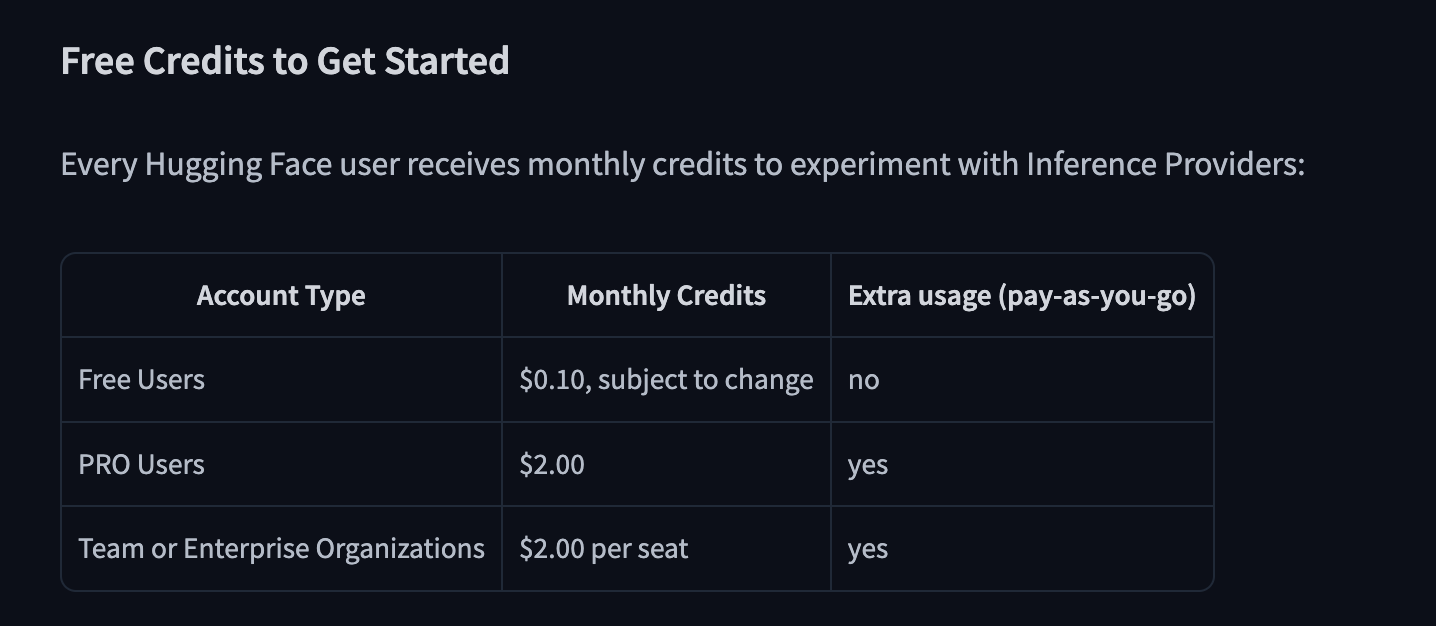
额度
免费用户每月有0.10美刀的额度,大概可以进行50-100次访问,升级为Pro用户后可以使用pay-as-you-go随时可以充值。
使用场景
虽然我把使用场景放到最后,但还是需要写一下。 HF推理模型可以快速地完成应用调用,而且HF上模型相对较多,相对,但不是所有。