前方高能,阅读本文需要大量预备知识,数据库,大数据 本文中的binlog号码只是为了解释整个过程,实际操作过程中可能产生多个binlog文件。
关键字
AWS Aurora MySQL, GTID(全局事务ID),CDC(Capture Data Change),Binlog,Debezium MySQL connector,Kafka,Snowflake
背景
稍微科普一下,GTID是一种全局事务ID,对于主从同步,灾难恢复有很大的帮助。
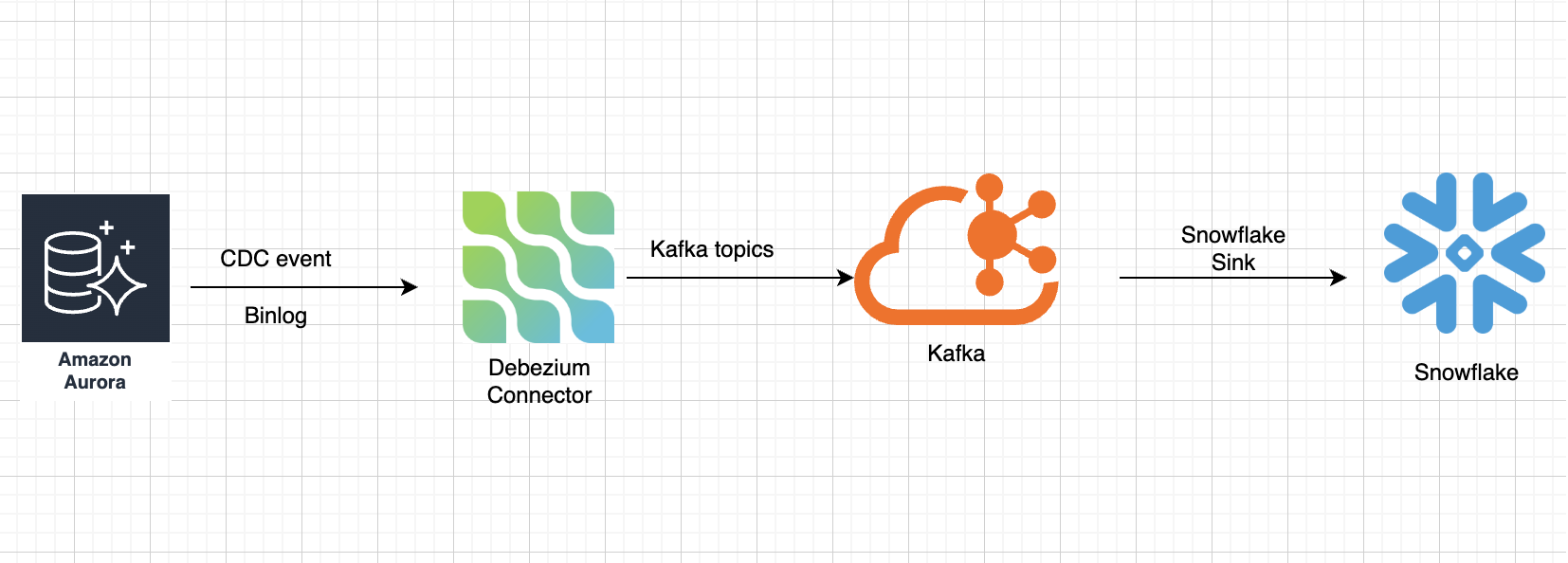
系统是一个实时的高频的交易数据库,仅写入请求的QPS就高达350,业务停机时不可能的。数据库为多库结构,每个数据库都是一主多从的集群结构。 利用MySQL的CDC功能结合Debezium MySQL connector将数据库实时同步到Kafka。用CDC的好处是非侵入性的,只读取binlog即可,可以不影响业务系统运行。数据消息进入Kafka之后,再由snowflake sink同步到Snowflake,在Snowflake上进行(准)实时数据分析。整体数据管道上的延迟大概小于5分钟。
难点
启动GTID的过程就是一个gtid_mode 和 enforce_gtid_consistency 开关,难点在于,一旦数据库重启使能了GTID,旧的CDC事件就无法再从binlog读出了。
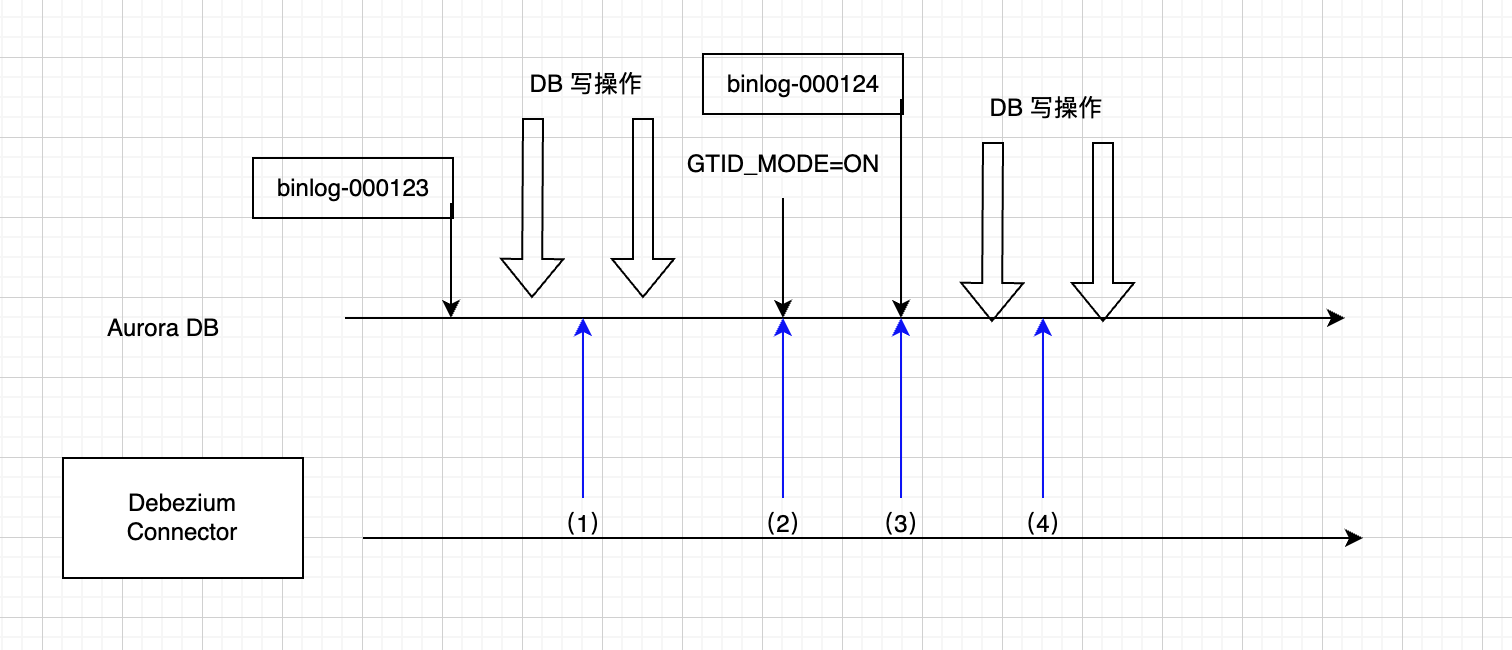
如下图所示,正常binlog创建之后,DBZ(debezium)是可以读取的,binglog.000123是包含匿名事务的,在时间点(1)处,数据库处在GTID为OFF的模式,所以读出binlog也没有问题,在时间点(2)服务器应用了GTID=ON(一般需要重启生效),重启后,新的binlog为000124,该binlog包含GTID的事务,但是从时间点(2)之后,服务器就只允许读取GTID事务的binlog了,也就是说,如果在(1)和(2)之间有数据库写操作并且还未被DBZ同步到kafka,那么这部分数据将无法同步到Kafka了,因为(2)之后从binlog读匿名事务就不允许了。
业务系统是不可能停止数据库(或者禁止写操作)的,所以为了确保所有数据可以被安全同步到Kafka,确保数据一致性,需要进行调整。
过渡
为了解决上述问题,这里要引入一个中间状态ON_PERMISSIVE. 当MySQL的GTID_MODE在ON_PERMISSIVE模式下,所有写操作都会带上GTID,但是仍然允许从binlog读取匿名事务以及GTID事务。
如下图,我们重新设计一下使能流程如下:
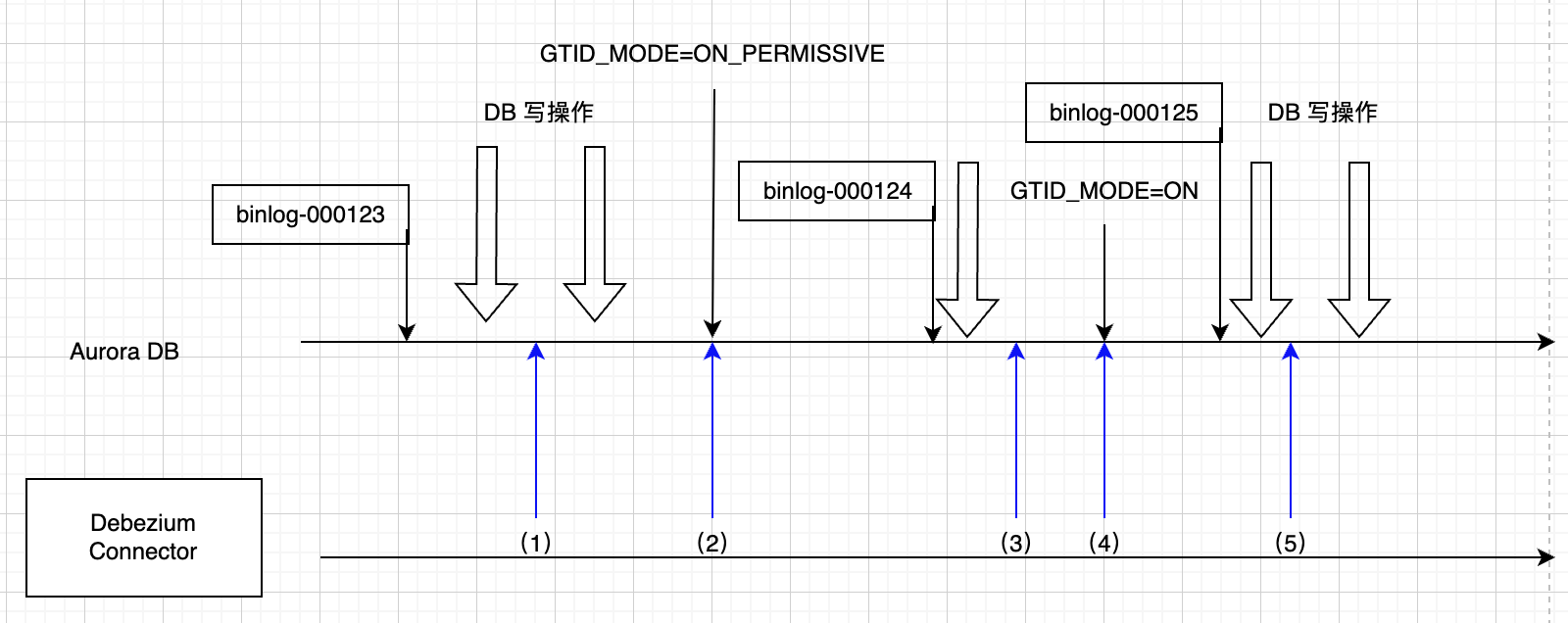
图中时间点(2)使能了ON_PERMISSIVE模式,在(2)之前的binlog.000123是包含匿名事务信息的,重启之后000124开始就只会包含GTID事务,而此时服务器仍然允许读取000123(包含匿名事务信息),所以我们只要保证在时间点(4)之前,把所有000123以及之前的binlog全部同步到kafka,就可以确保snowflake与aurora的数据一致性。在时间点(4)之后,系统完全进入GTID模式,也就是不再允许读取000123及之前的binlog。